Js引擎工作原理
这是一篇我自己翻译的前端基础博文,原作者是Lydia Hallie。 想看原文的小伙伴可以直接转到 🚀⚙️ JavaScript Visualized: the JavaScript Engine
here we go!
正文开始👉
🚀⚙️ JavaScript 可视化: JavaScript 引擎
JavaScript 很棒,但是一台电脑究竟是怎么理解你写的 Js 代码的?作为 JavaScript 开发人员,我们通常不需要自己处理编译的部分,然而,了解 JavaScript 引擎的基础并知道它是如何处理对人类友好的 JavaScript 代码的,并且将其转换成电脑可以理解的语言,绝对有利于我们。
提示:这篇博客观点主要基于使用 V8 引擎的 Node.js 和基于 Chromium 开发的浏览器。
首先 HTML parse 遇到了script标签和其指向的源(js文件),代码一般来自于网络或缓存,抑或是已安装的 service worker(PWA应用的离线文件),请求的script脚本响应回来是可以被解码器解码的字节流,解码器对响应回来的字节流进行解码。如下图
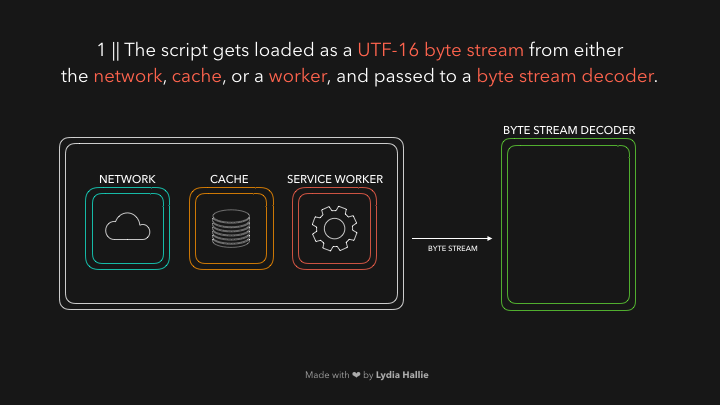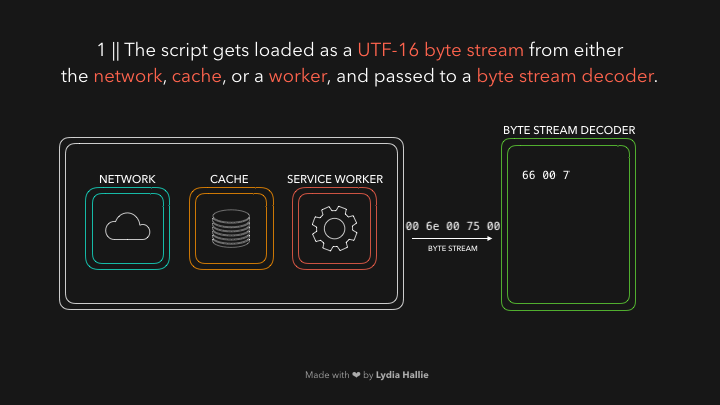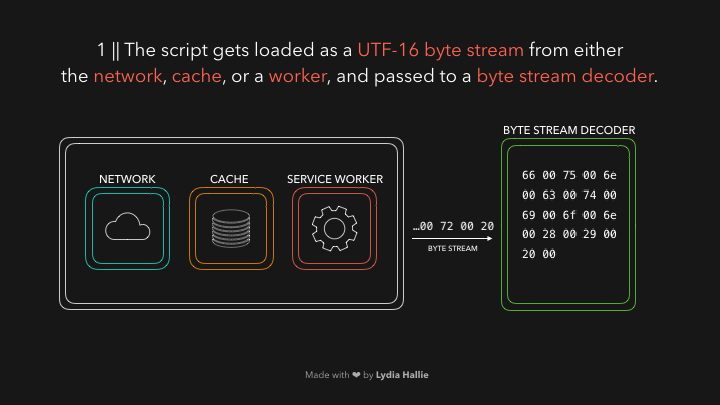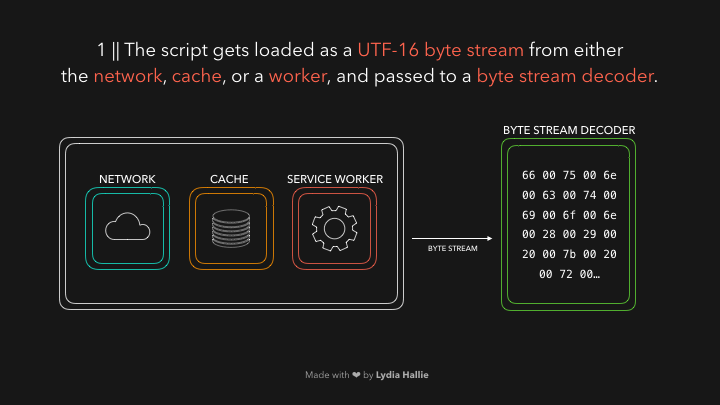
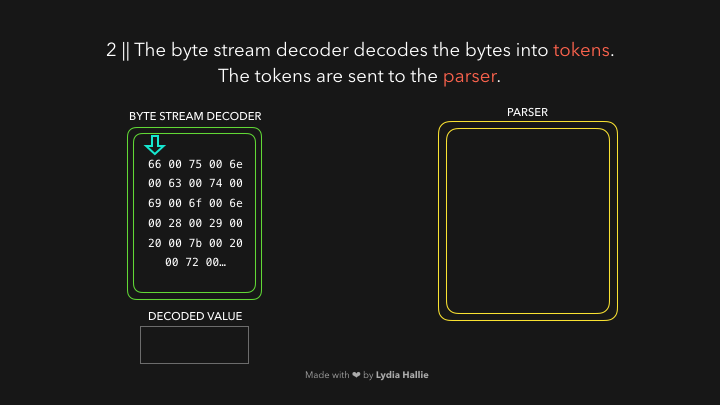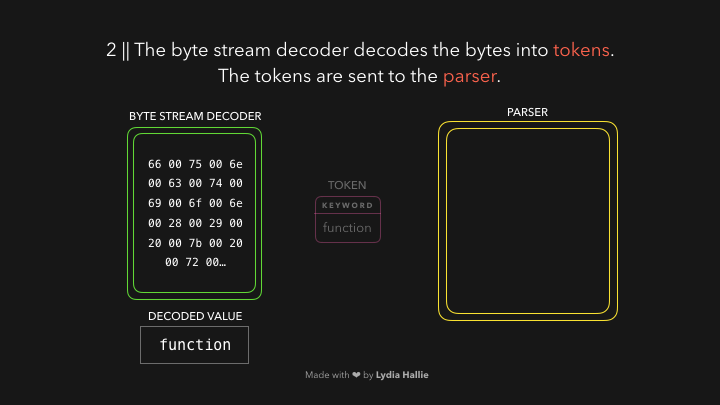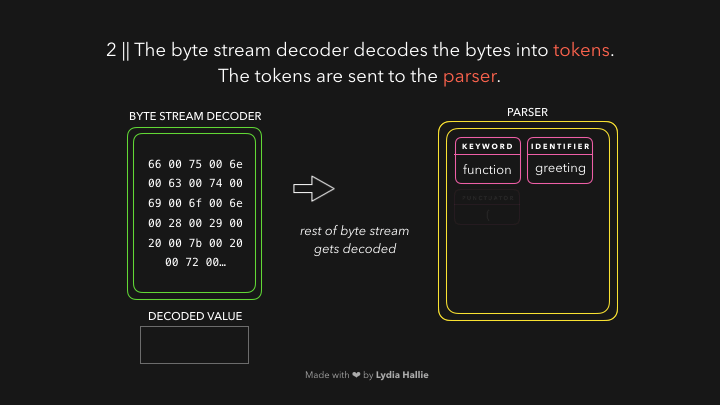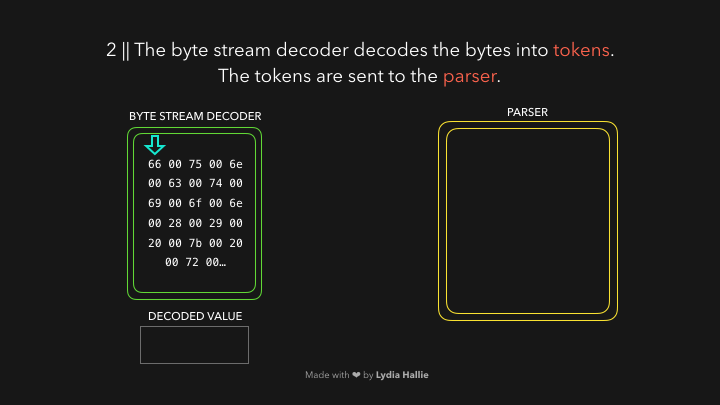
解码器会根据字节码来创建很多的 tokens ,举个栗子,0066解码为f,0075解码为u,006e解码为n,0063解码为c,0074解码为t,0069解码为i,006f解码为o,006e解码为n,紧跟着一个空白符,看起来就像是你写的function!这就是 JavaScript 的保留关键字,这样一个 token 就被创建好了,解下来发送给 parser 解析器(还有 pre-parser 预解析器,之后我会用 gif 图片解释它)。解码器会解码剩下的所有字节流。如下图
Js引擎会使用 2 个 parser:一个是 pre-parser 预解析器,一个是 parser 解析器。为了减少网站加载的时间,Js引擎尝试避免解析不必要的代码,预解析器会处理稍后用到的代码,解析器会处理马上需要的代码,如果确定一个function只会在用户点击按钮时执行,那这就是不必要在加载网页时直接解析的,如果用户最终点击按钮并需要那段代码,它就会发送给解析器。
解析器会基于从字节流解码器那儿获得的 tokens 创建很多 node 节点,有了这些节点,它就可以创建抽象语法树🌳(Abstract Syntax Tree 简称 AST)。
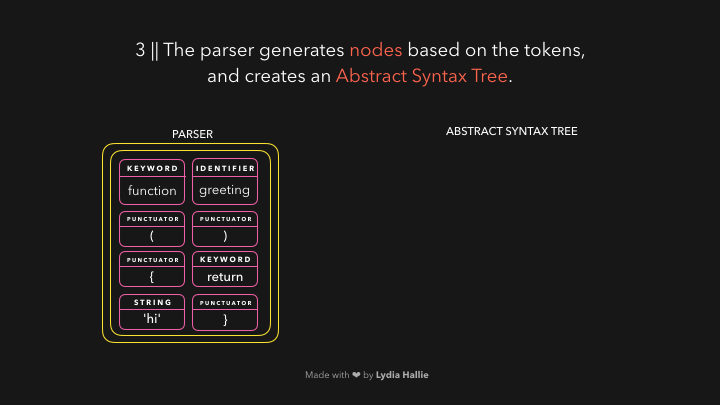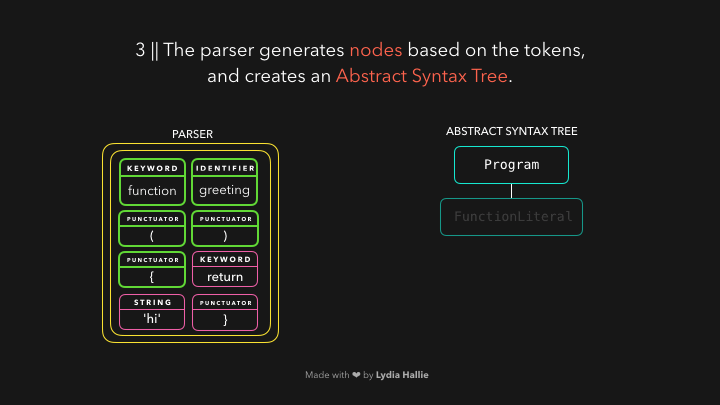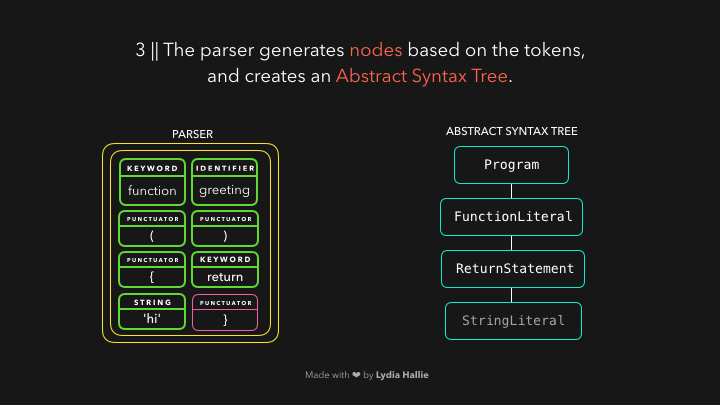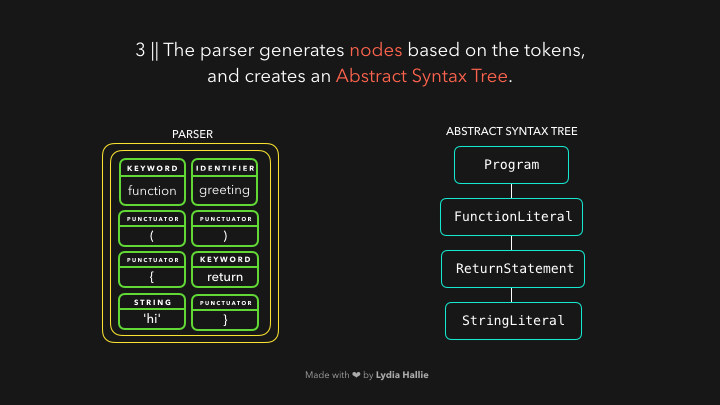
接下来,该 interpreter(解释器)上场了,解释器会沿着 AST 的结构和 AST 包含的信息生成字节码(byte code),一旦字节码被全部生成完毕,AST 会被删除,并清理内存空间,最后,我们就得到了计算机可以使用的东西了🎉。

尽管字节码的执行效率很快,但还可以更快。当字节码运行时,信息会被记录,用来检测出确定经常发生的行为,和经常使用到的数据的类型。或许你可以这样理解,一个你已经调用了几十次的函数:它是时候优化了,以便让它可以执行得更快!🏃🏽♀️
这个时候这段字节码和数据的类型反馈,被发送给了 optimizing compiler(优化编译器)。优化编译器拿到它们后,会生成经过高度优化的机器码。🚀

JavaScript 是动态类型语言,这意味着数据类型可以被经常改变。这会实实在在放慢 JavaScript 引擎每次检查数据类型和它确切的值的时间。
为了节省解释代码消耗的时间,优化后的机器码只处理引擎在运行字节码时遇到过的情况。如果我们重复的使用一段确定的代码而且总是返回相同的数据类型,优化后的机器码就是被用来提升这类代码执行的效率的,然而,毕竟 JavaScript 是动态类型的语言,所以它的确可能发生一段相同的代码突然返回不同的数据类型的情况,如果这发生了,这段机器码会被 de-optimized (去优化),并且引擎会回退到之前解释器生成的字节码。
如果说一个确定的函数已经被执行了100次,总是返回了相同的值,那么引擎会假设第101次执行也会返回相同的值。
假设我们有以下函数sum,(到目前为止)总是以数值值作为参数来调用:

这里返回了数字3!下一次我们再执行它,引擎会假设我们会再次传入 2 个数字类型的参数来调用它。
如果的确如此,无需动态查找,它就会被重用为优化后的机器码,反之,如果引擎的假设错误,换言之你调用并非按照引擎的假设来,它就会被回复为原始的字节码。
举个例子,我们下一次的调用,传入了一个 string 类型的值,得益于 JavaScript 的动态类型的特性,我们确实可以这样做,并且不会有任何报错。

这意味着传入的 number 类型的2会被强制转化为 string 类型,函数的执行结果会变成"12",引擎就会回去执行字节码并更新类型反馈。
😊okk~ 翻译完了,纯人工翻译,希望能够帮到各位,如有纰漏,欢迎指正~